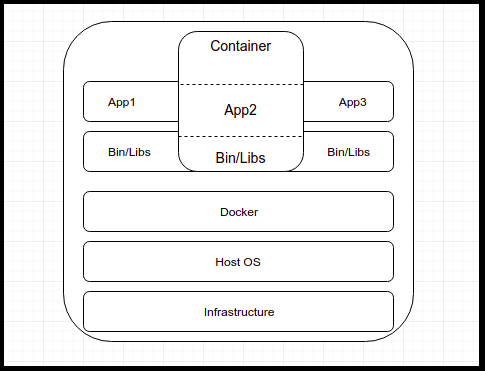
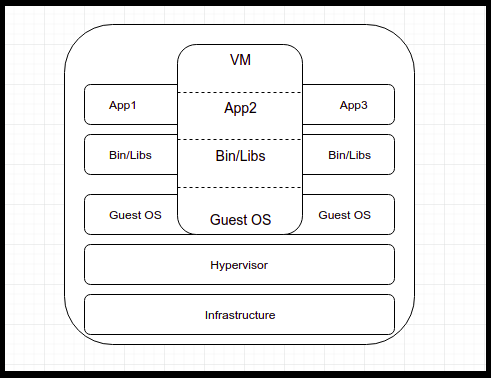
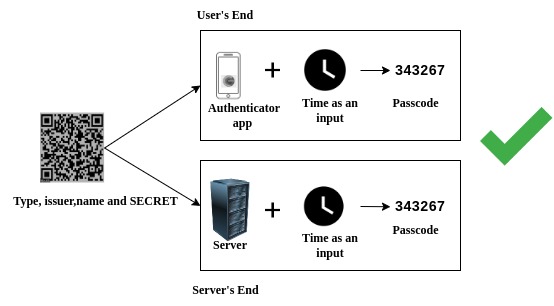
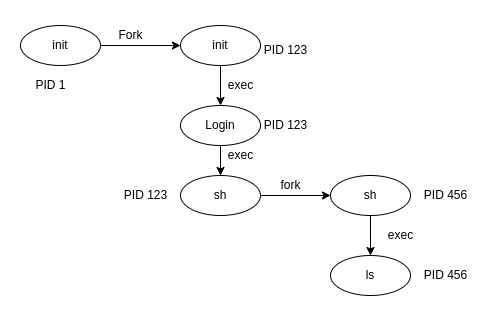
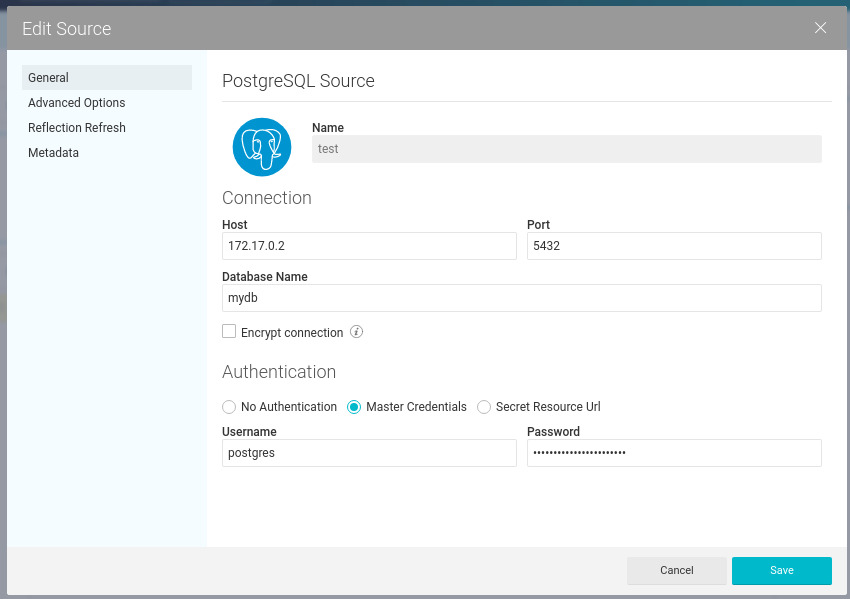
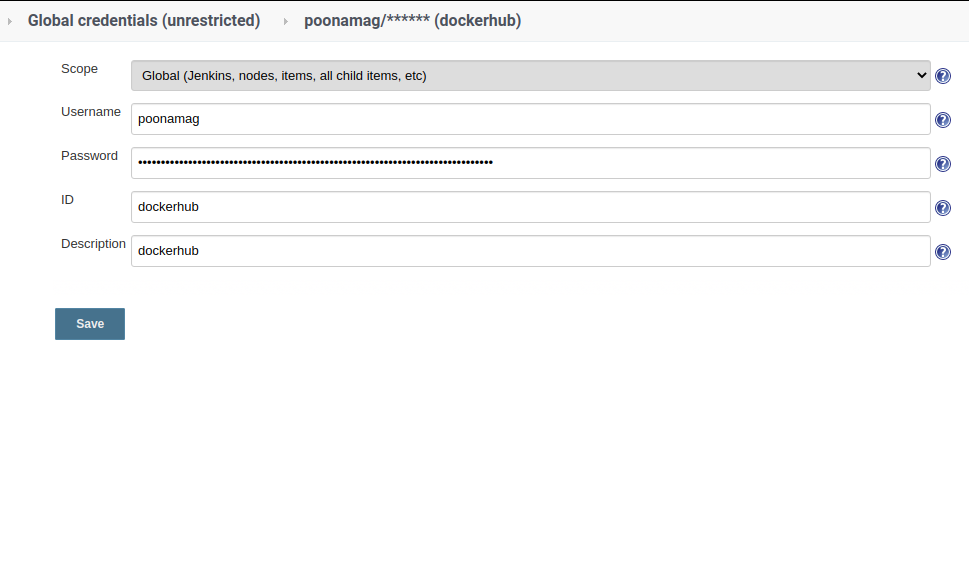
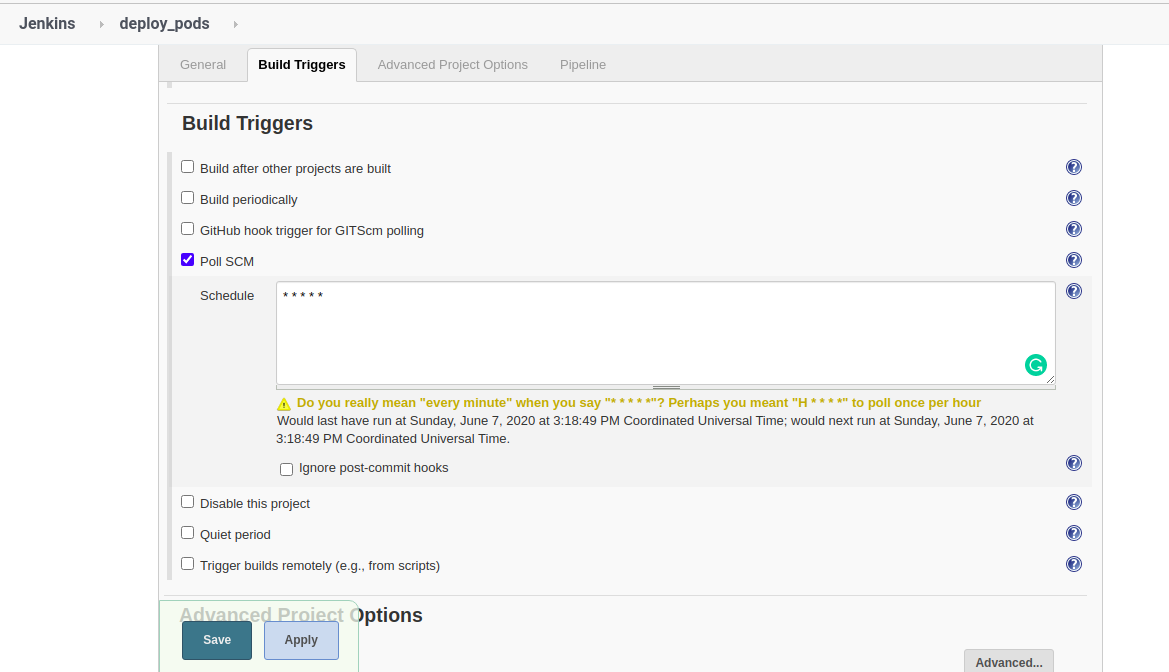
Understanding CPU load Average On the basis of following variables:
- CPU cores.
- CPU load average.
- CPU load average on the basis of number of CPU.
CPU Cores
- We can check the number of cpu cores by one of the following commands:
$ nproc
4
OR
lscpu
$ grep ‘model name’ /proc/cpuinfo | wc -l
4
CPU load average
- We can check load on the cpu with the following commands:
$ cat /proc/loadavg
2.48 1.69 1.42 5/889 10570
$ cat /proc/loadavg
2.48 1.69 1.42 5/889 10570
top - 00:07:16 up 5:36, 1 user, load average: 0.86, 0.78, 0.77
Tasks: 312 total, 1 running, 256 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.7 us, 0.8 sy, 0.0 ni, 96.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8033996 total, 1619612 free, 3388332 used, 3026052 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 3859444 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3059 poonam 20 0 3839156 223956 74324 S 3.3 2.8 2:53.46 gnome-shell
2913 poonam 20 0 399424 85528 58908 S 3.0 1.1 1:38.02 Xorg
9269 poonam 20 0 679612 56704 34448 S 2.0 0.7 0:01.05 terminator
8075 poonam 20 0 407236 98308 9112 S 1.3 1.2 2:42.54 plugin_host
$ uptime
00:08:07 up 5:36, 1 user, load average: 0.84, 0.78, 0.78
$ cat /proc/loadavg
0.96 0.82 0.79 1/1269 10197
CPU load average on the basis of number of CPU
Let’s say we have load averages below:
23:16:49 up 10:49, 5 user, load average: 1.00, 0.40, 3.35
On a single core system this would mean:
-
The CPU was fully (100%) utilized on average; 1 processes was running on the CPU (1.00) over the last 1 minute.
-
The CPU was idle by 60% on average; no processes were waiting for CPU time (0.40) over the last 5 minutes.
-
The CPU was overloaded by 235% on average; 2.35 processes were waiting for CPU time (3.35) over the last 15 minutes.
On a dual-core system this would mean:
-
The one CPU was 100% idle on average, one CPU was being used; no processes were waiting for CPU time(1.00) over the last 1 minute.
-
The CPUs were idle by 160% on average; no processes were waiting for CPU time. (0.40) over the last 5 minutes.
-
The CPUs were overloaded by 135% on average; 1.35 processes were waiting for CPU time. (3.35) over the last 15 minutes.
 April 24, 2018 and it all began…
April 24, 2018 and it all began… April 25, 2018 mornings started like this…
April 25, 2018 mornings started like this… and this one April 26 2018…
and this one April 26 2018… April 27 2018 …
April 27 2018 … May 1st 2018 another one to present somebody…
May 1st 2018 another one to present somebody… May 2nd 2018 was also awesome…
May 2nd 2018 was also awesome… May 5th 2018 with some break now…
May 5th 2018 with some break now… October 07 2018 and busy again with some goals….
October 07 2018 and busy again with some goals…. August 05 2019 and I am back!
August 05 2019 and I am back! August 07 2019 and Dreaming about someone…
August 07 2019 and Dreaming about someone… August 09 2019 Just the imagination..
August 09 2019 Just the imagination.. August 10 2019 Imperfections around but perfect together..
August 10 2019 Imperfections around but perfect together.. August 10 2019 grandpa :-)
August 10 2019 grandpa :-) August 12 2019 A view of Kashmir… (use of water color)
August 12 2019 A view of Kashmir… (use of water color)